服务器演变过程#
了解K8S之前,首先需要了解服务器的演变过程:
- 物理机时代
- 虚拟机时代
- 容器化时代
物理机时代#
缺点:
- 部署慢 :每台服务器都要安装操作系统、相关应用程序所需要的环境,各种配置
- 成本高:物理服务器的价格十分昂贵
- 资源浪费:硬件资源不能充分利用
- 扩展和迁移成本高:扩展和迁移需要重新配置一模一样的环境
虚拟机时代#
虚拟机时代解决了物理机时代的缺点,虚拟机时代的优点是:
- 易部署:每台物理机可部署多台虚拟机,还可以通过模板,部署快,成本低
- 资源池:开出来的虚拟机可作为资源池备用,充分压榨服务器性能
- 资源隔离:每个虚拟机都有独立分配的内存磁盘等硬件资源,虚拟机之间不会互相影响
- 易扩展:随时都能在一个物理机上创建或销毁虚拟机
缺点:每台虚拟机都需要安装操作系统
容器化时代#
容器化时代解决了虚拟机时代的缺点,在继承了虚拟机时代优点的基础上,还有以下优势:
- 更高效的利用硬件资源:所有容器共享主机操作系统内核,不需要安装操作系统
- 一致的运行环境:相同的镜像产生相同的行为
- 更小:较虚拟机而言,容器镜像更小,因为不需要打包操作系统
- 更快:容器能达到秒级启动,其本质是主机上的一个进程
Kubernetes 简介#
Kubernetes 是谷歌开源的容器集群管理系统,用于管理容器化工作负载和服务。是 Google 多年大规模容器管理技术 Borg 的开源版本,主要功能包括:
- 基于容器的应用部署、维护和滚动升级
- 负载均衡和服务发现
- 跨机器和跨地区的集群调度
- 自动伸缩
- 无状态服务和有状态服务
- 广泛的 Volume 支持
- 插件机制保证扩展性
Kubernetes 发展非常迅速,目前已成为容器编排领域的领导者。
参考文档: https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/
Kubernetes 相关组件#
Kubernetes 主要由以下几个核心组件组成:
etcd:保存整个集群的状态apiserver:提供资源操作的唯一入口,并提供认证、授权、访问控制、API 注册和发现等机制controller manager:负责维护集群的状态,比如故障检测、自动扩展、滚动更新等scheduler:负责资源的调度,按照预定的调度策略将 Pod 调度到相应的机器上kubelet:负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理Container runtime:负责镜像管理以及 Pod 和容器的真正运行(CRI)kube-proxy:负责为 Service 提供 Cluster 内部的服务发现和负载均衡
除了核心组件,还有一些推荐的附加组件:
kube-dns:负责为整个集群提供 DNS 服务Ingress Controller:为服务提供外网入口Heapster:提供资源监控Dashboard:提供 GUIFederation:提供跨可用区的集群Fluentd-elasticsearch:提供集群日志采集、存储与查询
Etcd#
Etcd 是 CoreOS 基于 Raft 开发的分布式 key-value 存储,可用于服务发现、共享配置以及一致性保障(如数据库选主、分布式锁等)。项目地址:https://github.com/etcd-io/etcd
主要功能:
- 基本的 key-value 存储
- 监听机制
- key 的过期及续约机制,用于监控和服务发现
- 原子CAS 和 CAD,用于分布式锁和 leader 选举
Kube-apiserver#
kube-apiserver 是 Kubernetes 最重要的核心组件之一。
主要功能:
- 提供集群管理的 REST API 接口,包括认证授权、数据校验以及集群状态变更等
- 提供其他模块之间的数据交互和通信的枢纽(其他模块通过 API Server 查询或修改数据,只有 API Server 才直接操作 etcd)
Controller-manager#
Controller Manager 由 kube-controller-manager 和 cloud-controller-manager 组成,是 Kubernetes 的大脑。通过 apiserver 监控整个集群的状态,并确保集群处于预期的工作状态。
kube-controller-manager 由一系列的控制器组成:
- Replication Controller
- Node Controller
- CronJob Controller
- Daemon Controller
- Deployment Controller
- Endpoint Controller
- Garbage Collector
- Namespace Controller
- Job Controller
- Pod AutoScaler
- RelicaSet
- Service Controller
- ServiceAccount Controller
- StatefulSet Controller
- Volume Controller
- Resource quota Controller
cloud-controller-manager
在 Kubernetes 启用 Cloud Provider 时才需要,用来配合云服务提供商的控制,也包括一系列的控制器,如:
- Node Controller
- Route Controller
- Service Controller
Scheduler#
kube-scheduler 负责分配调度 Pod 到集群内的节点上,它监听 kube-apiserver,查询还未分配 Node 的 Pod,然后根据调度策略为这些 Pod 分配节点(更新 Pod的 NodeName 字段)。
调度器需要充分考虑诸多的因素:
- 公平调度
- 资源高效利用
- Qos
- affinity 和 anti-affinity
- 数据本地化(data locality)
- 内部负载干扰(inter-workload interference)
- deadlines
Kubelet#
每个节点上都运行一个 kubelet 服务进程,默认监听 10250 端口,接收并执行 master 发来的指令,管理 Pod 及 Pod 中的容器。每个 kubelet 进程会在 API Server 上注册节点自身信息,定期向 master 节点汇报节点的资源使用情况,并通过 cAdvisor 监控节点和容器的资源。
Container runtime#
容器运行时(Container Runtime)是 Kubernetes 最重要的组件之一,负责真正管理镜像和容器的生命周期。Kubelet 通过 Container Runtime Interface (CRI) 与容器运行时交互,以管理镜像和容器。
Kube-proxy#
每台机器上都运行一个 kube-proxy 服务,用于监听 API server 中 service 和 endpoint 的变化情况,并通过 iptables 等来为服务配置负载均衡(仅支持 TCP 和 UDP)。
kube-proxy 可以直接运行在物理机上,也可以以 static pod 或者 daemonset 的方式运行。
kube-proxy 当前支持以下几种实现:
userspace:最早的负载均衡方案:在用户空间监听一个端口,所有服务通过iptables转发到这个端口,然后在其内部负载均衡到实际的 Pod。该方式最主要的问题是:效率低,有明显的性能瓶颈iptables:目前推荐的方案:完全以iptables规则的方式来实现 service 负载均衡。该方式最主要的问题是:在服务多的时候产生太多的iptables规则,非增量式更新会引入一定的延时,大规模情况下有明显的性能问题ipvs:为解决 iptables 模式的性能问题,v1.8 新增了ipvs模式,采用增量式更新,并可以保证 service 更新期间连接保持不断开winuserspace:同 userspace,但仅工作在 windows 上
Kubernetes 架构#
Kubernetes 借鉴了 Borg 的设计理念,比如Pod、Service、Labels等。整体架构跟 Borg 非常像,如下图所示:
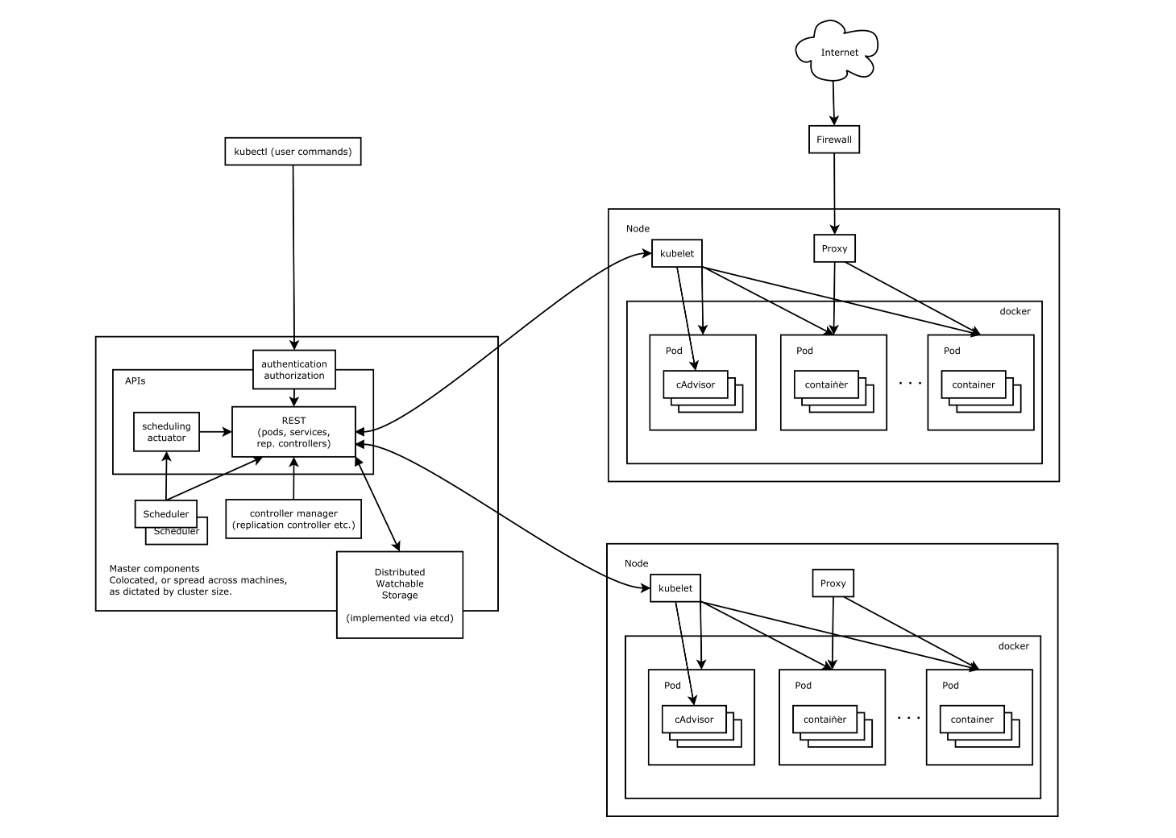
在 K8S 中,由 Master 控制节点和 Worker 节点共同构成一个集群。
Master#
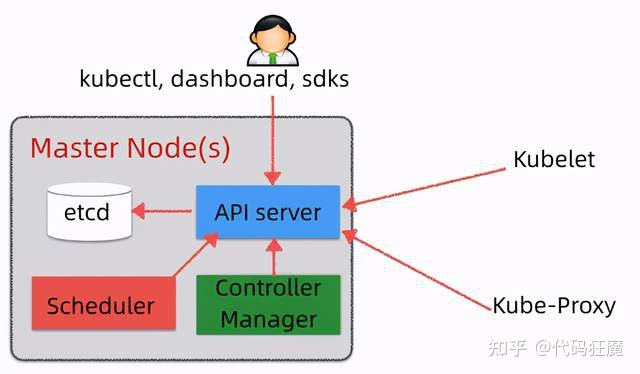
- Etcd:用于保存集群中的相关数据
- Api Server:集群统一入口,以 restful 风格操作,同时交给 etcd 存储(是唯一能访问etcd的组件)提供认证、授权、访问控制、API注册和发现等机制,可以通过 kubectl 命令行工具,dashboard 可视化面板,或者sdk 等方式访问
- Scheduler:节点的调度,选择 node 节点进行应用部署
- Controller Manager:处理集群中常规后台任务,一个资源对应一个控制器,同时监控集群状态,确保实际状态和最终状态一致
Worker#
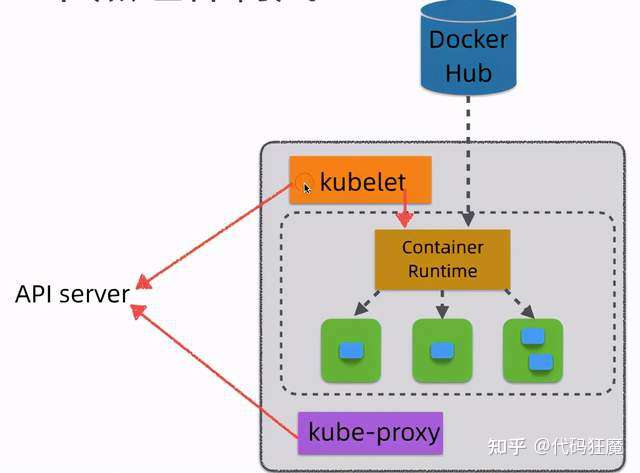
- kubelet:相当于 Master 派到 node 节点代表,管理本机容器,上报数据给 API Server
- Container Runtime:容器运行时,K8S支持多个容器运行环境:Docker、Containerd、CRI-O、Rktlet 以及任何实现 Kubernetes CRI (容器运行环境接口) 的软件
- kube-proxy:实现服务(Service)抽象组件,屏蔽 PodIP 的变化和负载均衡
镜像库在 Kubernetes 中也起到一个很重要的角色,Kubernetes 需要从镜像库中拉取镜像基于这个镜像的容器才能成功启动。常用的镜像库有 dockerhub、阿里云镜像库、Harbor等
Kubernetes 核心概念#
Pod#
- Pod 是最小调度单元
- Pod 包含一个或多个容器(Container)
- Pod 内的容器共享存储及网络,可通过
localhost通信
Pod 本意是豌豆荚的意思,此处指 K8S 中资源调度的最小单位,豌豆荚里面的小豆子就像是 Container,豌豆荚本身就像是一个 Pod。
Deployment#
Deployment 是在 Pod 抽象上更为上层的一个抽象,它可以定义一组 Pod 的副本数目、以及这个 Pod 的版本。一般用 Deployment 这个抽象来做应用的真正管理,Pod 是组成 Deployment 最小的单元。
- 定义一组 Pod 的副本数量,版本等
- 通过控制器维护 Pod 的数目
- 自动恢复失败的 Pod
- 通过控制器以指定的策略控制版本
Service#
Pod 是不稳定的,IP 会变化,所以需要一层抽象来屏蔽这种变化,这层抽象叫做 Service
- 提供访问一个或者多个 Pod 实例稳定的访问地址
- 支持多种访问方式 ClusterIP(对集群内部访问)、NodePort(对集群外部访问)、LoadBalancer(集群外部负载均衡)
Volume#
Volume 就是存储卷。在 Pod 中可以声明卷来问访问文件系统,同时 Volume 也是一个抽象层,其具体的后端存储可以是本地存储、NFS 网络存储、云存储(阿里云盘、AWS云盘、Google云盘等)、分布式存储(比如 ceph、GlusterFS )
- 声明在 Pod 中容器可以访问的文件系统
- 可以被挂载在 Pod 中一个或多个容器的指定路径下
- 支持多种后端存储
Namespace#
Namespace(命令空间)是用来做资源的逻辑隔离的,比如 Pod、Deployment、Service 都属于资源,不同Namespace 下资源可以重名。同一 Namespace 下资源名必须唯一。
- 一个集群内部的逻辑隔离机制(鉴权、资源等)
- 每个资源都属于一个 Namespace
- 同一个 Namespace 中资源命名唯一
- 不同 Namespace 中资源可重名