Elasticsearch 简称 ES,是一个开源、高扩展的分布式全文检索引擎,可以实现近乎实时的存储、检索数据且扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。ES 底层是开源库 Lucene,ES 实现了对 Lucene 的封装,并提供 REST 风格的操作接口开箱即用。通过简单的 RESTful API 来隐藏Lucene的复杂性,从而让全文搜索变得简单。
ElasticSearch 对比 Solr#
- Solr 利用
Zookeeper进行分布式管理, Elasticsearch 自身带有分布式协调管理功能 - Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能由第三方插件提供
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch
ElasticSearch 安装#
注意:ES 使用 Java 开发,使用 Lucene 作为核心,所以需要配置好java环境(
jdk1.8以上)
下载地址:ElasticSearch 官网,如果下载比较慢可以试试:newbe.pro
Windows 平台下载完成直接解压即可,目录结构如下:
bin // 可执行二进制文件
config // 配置信息目录
lib // jar包存放目录,比如lucene相关的jar包
logs // 日志
modulES // 模块
plugins // 插件ElasticSearch 配置#
调整内存#
修改 conf\jvm.option 文件
-Xms1g
-Xmx1g
修改为自己定义的值,比如
-xms256m
-xmx256m
防止因为内存不足无法启动开启跨域#
修改 conf\elasticsearch.yml 文件,在末尾加入如下代码:
http.cors.enabled: true
http.cors.allow-origin: "*"
network.host: 127.0.0.1ElasticSearch 启动#
双击 bin 目录下的 elasticsearch.bat 启动:
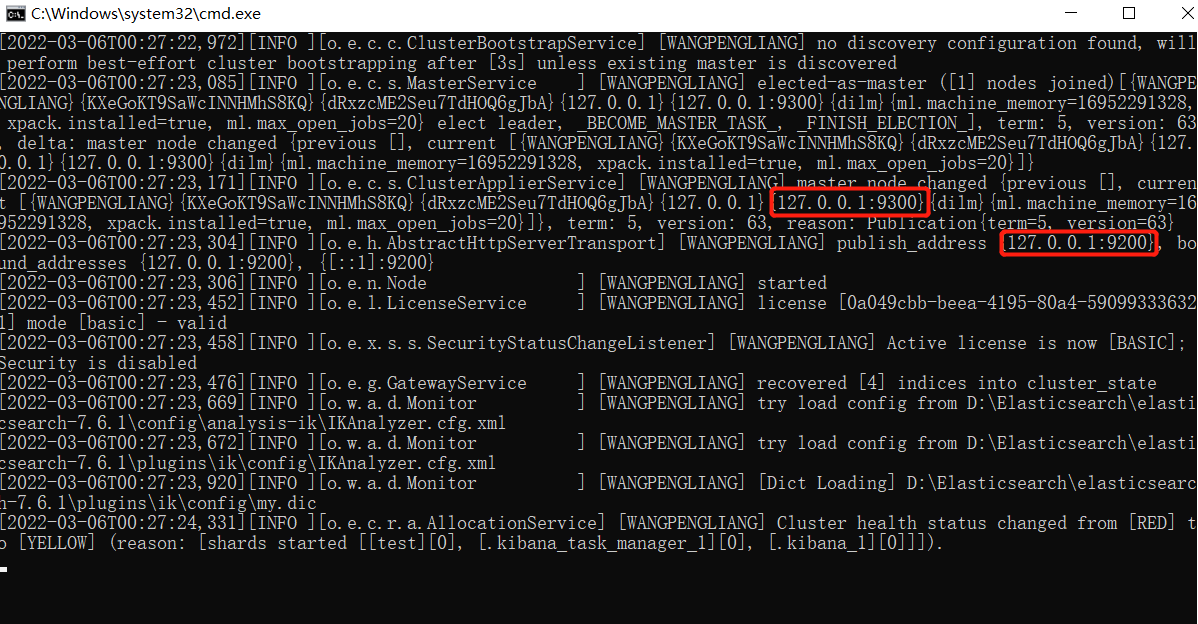
:warning: ES集群之间使用tcp进行通信,
9300是tcp通信端口,9200是http协议端口
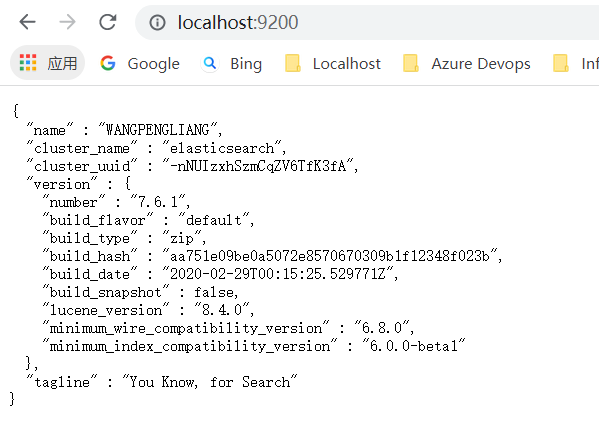
浏览器测试访问:
Elasticsearch-head#
通过安装 ElasticSearch 的 head 插件,可以实现图形化查看索引数据。下载地址
下载完成后解压即可,目录结构如下:
Elasticsearch-head 依赖于 node.js 所以需要先保证本地有 node.js 的环境:
C:\Users\Administrator>node -v
v14.17.3使用 npm 还原依赖:
D:\Elasticsearch\elasticsearch-head-master>npm install注意:如果下载速度较慢,可以切换淘宝镜像使用 cnpm
启动 Elasticsearch-head:
D:\Elasticsearch\elasticsearch-head-master>npm run start
> elasticsearch-head@0.0.0 start D:\Elasticsearch\elasticsearch-head-master
> grunt server
Running "connect:server" (connect) task
Waiting forever...
Fatal error: Port 9100 is already in use by another procESs.
npm ERR! code ELIFECYCLE
npm ERR! errno 1
npm ERR! elasticsearch-head@0.0.0 start: `grunt server`
npm ERR! Exit status 1
npm ERR!
npm ERR! Failed at the elasticsearch-head@0.0.0 start script.
npm ERR! This is probably not a problem with npm. There is likely additional logging output above.
npm ERR! A complete log of this run can be found in:
npm ERR! C:\Users\Administrator\AppData\Roaming\npm-cache\_logs\2022-03-05T16_39_04_056Z-debug.log这里报错:Port 9100 is already in use by another procESs. ,原因是 9100 端口被占用,查看哪个进程占用的端口号并结束该进程:
D:\Elasticsearch\elasticsearch-head-master>netstat -ano | findstr "9100"
TCP 0.0.0.0:9100 0.0.0.0:0 LISTENING 12276
TCP 127.0.0.1:53459 127.0.0.1:9100 TIME_WAIT 0
D:\Elasticsearch\elasticsearch-head-master>taskkill -pid 12276 -F
成功: 已终止 PID 为 12276 的进程。重新启动:
D:\Elasticsearch\elasticsearch-head-master>npm run start
> elasticsearch-head@0.0.0 start D:\Elasticsearch\elasticsearch-head-master
> grunt server
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100浏览器访问:

ok,至此完成 Elasticsearch-head 的安装启动。
Elasticsearch 核心概念#
Elasticsearch 是面向文档(document oriented )的,这意味着它可以存储整个对象或文档(document )。然而它不仅会存储,还会索引( index )每个文档的内容使之可以被搜索。在Elasticsearch中,可以对文档(而非成行或列的数据)进行索引、搜索、排序、过滤。Elasticsearch 对比传统关系型数据库如下:
RDBMS ‐> DatabasES ‐> TablES ‐> Rows ‐> Columns Elasticsearch ‐> IndicES ‐> TypES ‐> Documents ‐> Fields
index 索引#
一个索引就是一个拥有几分相似特征的文档的集合。比如客户数据索引、产品目录索引、订单数据索引。索引由一个名字来标识(名称必须全部小写),当要对这个索引中的文档进行索引、搜索、更新和删除时都要使用到这个名字。一个集群中可以定义任意多的索引。可类比SqlServer中的数据库
type 类型#
一个索引中可以定义一种或多种类型。一个类型是索引的一个逻辑上的分类/分区,其语义完全自己定义。通常会为具有一组共同字段的文档定义一个类型。假设运营一个博客平台并且将所有的数据存储到一个索引中。在这个索引中,可以为用户数据定义一个类型,为博客数据定义另一个类型。可类比SqlServer中的表
:rotating_light: 注意:ES 7.0 以及之后的版本中 Type 被废弃。一个 index 中只有一个默认的 type,即
_doc
Filed字段#
相当于数据表的字段,对文档数据根据不同属性进行的分类标识 。
mapping 映射#
mapping 在处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都可以在映射里设置,其它就是处理ES里面数据的一些使用规则设置也叫做映射,按最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。相当于SqlServer中的创建表的过程,设置主键外键等等
document 文档#
一个文档是一个可被索引的基础信息单元。比如:客户文档、产品文档。文档以JSON(
Javascript Object Notation)格式表示。一个index/type里可以存储任意多的文档。注意:尽管一个文档物理上存在于一个索引之中,但文档必须被索引赋予一个索引的type。 插入索引库以文档为单位,类比与数据库中的一行数据
cluster 集群#
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认是“elasticsearch”。一个节点只能通过指定某个集群的名字,来加入这个集群。
node 节点#
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。一 个节点由一个名字来标识,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动时候赋予节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做
elasticsearch的集群中,这意味着,如果网络中启动了若干个节点,并假定它们能够相互发现彼此, 它们将会自动地形成并加入到一个叫elasticsearch的集群中。
一个集群里可以拥有任意多个节点。而且如果当前网络中没有运行任何 Elasticsearch 节点, 这时启动一个节点,会默认创建并加入一个叫做
elasticsearch的集群。
shards 分片#
一个索引可以存储超出单个节点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch 提供了将索引划分成多份的能力,这些份就叫做分片。当创建一个索引时,可以指定想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。分片很重要,主要有两方面的原因:
- 允许水平分割/扩展内容容量
- 允许在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量
至于一个分片怎样分布,它的文档怎样聚合返回给搜索请求,是完全由Elasticsearch管理的,对于用户来说这些都是透明的。
replicas 复制#
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制之所以重要,有两个主要原因
- 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。
- 扩展搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,可以在任何时候动态地改变复制的数量,但是事后不能改变分片的数量。
默认情况下,Elasticsearch 中的每个索引被分片5个主分片和1个复制,这意味着如果集群中有两个节点,索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。